如今的大数据技术应用场景,对实时性的要求已经越来越高。作为新一代大数据流处理框架,由于非常好的实时性,Flink独树一帜,在近些年引起了业内极大的兴趣和关注。Flink能够提供毫秒级别的延迟,同时保证了数据处理...
”大数据 flink 技术原理“ 的搜索结果

FlinkTutorial 专注大数据Flink流试处理技术。从基础入门、概念、原理、实战、性能调优、源码解析等内容,使用Java开发,同时含有Scala部分核心代码。欢迎关注我的博客及github。
华为教程,内容由浅入深,适合各个层次学习,欢迎大家讨论

尚硅谷大数据Flink1.17实战教程-笔记02【部署】

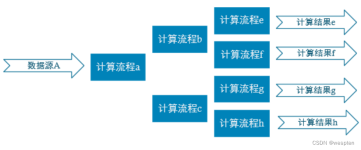
在本次实验中,主要是学习掌握基本的Flink编程方法编写Flink程序的方法以及对大数据的基础编程技能进行巩固。并且还学习了Flink的基本原理和运行机制,还通过具体的代码实现,了解到Flink程序的编写步骤和注意事项。...

Flink SQL大数据项目实战课程以FlinkSQL流批一体技术为主线,全面讲解Flink Table编程、SQL编程、Time与WaterMark、Window操作、函数使用、元数据管理,最后以一个完整的实战项目为例,详细讲解FlinkSQL的流式项目...
大数据预处理方法包括___数据清洗___、___数据集成_____、___数据变换___和___数据规约_____。
Flink是一个对有界和无界数据流进行有状态计算的分布式处理引擎和框架,既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型,其代码主要由 Java 实现,部分代码由 Scala...
视频详细讲解,需要的小伙伴自行网盘下载,链接见附件,永久有效。 课程介绍 ...更为用户调研了Flink的Flink CDC 2.0,基于1.x的技术痛点,2.0给出了更优化的解决方案,教程结合源码深入分析了其核心原理。
Flink原理与实践-PPT课件.rar
Flink核心技术及原理前言Flink简介统一的批处理与流处理Flink流处理的容错机制 前言 Apache Flink(简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的...
大数据不仅仅是数据的“大量化”,而是包含“快速化”、“多样化”和“价值化”等多重属性。两大核心技术:分布式存储和分布式处理大数据计算模式大数据具有数据量大、数据类型繁多、处理速度快、价值密度低等特点。

本篇博客我们将介绍搭建 Flink 时所涉及的不同组件并讨论它们在应用运行时的交互过程。我们主要讨论两类部署 Flink 应用的方式以及它们如何分配和执行任务。最后,我们将解释 Flink 高可用模式的工作原理。

本文是《大数据Flink学习圣经》 V1版本,是 《尼恩 大数据 面试宝典》姊妹篇。这里特别说明一下:《尼恩 大数据 面试宝典》5个专题 PDF 自首次发布以来, 已经汇集了 好几百题,大量的大厂面试干货、正货 。 《尼恩 ...
一、数据核心原理——从“流程”核心转变为“数据”核心 大数据时代,计算模式也发生了转变,从“流程”核心转变为“数据”核心。hadoop体系的分布式计算框架已经是“数据”为核心的范式。非结构化数据及分析需求,...
大数据Flink从入门到原理到电商数据分析实战项目 张长志技术全才、擅长领域...

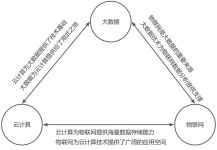
专栏简介 :本专栏主要分享收集的大数据相关的面试题,涉及到Hadoop,Spark,Flink,Zookeeper,Flume,Kafka,Hive,Hbase等大数据相关技术。大数据面试专栏地址。 ???? 个人主页 :大数据小禅 ???? 粉丝福利 :...

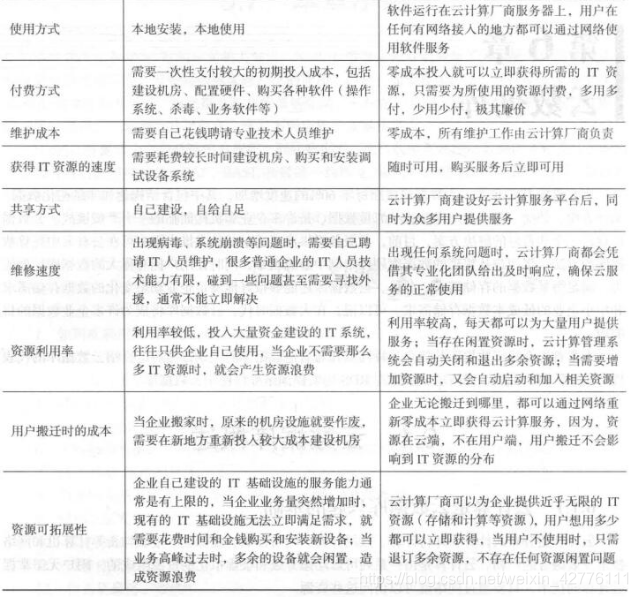
第1讲 大数据概述答案 第2讲 大数据处理架构Hadoop答案 第3讲 分布式文件系统HDFS答案 第4讲 分布式数据库HBase答案 第5讲 NoSQL数据库答案 第6讲 云数据库答案 第7讲 MapReduce答案 第8讲 数据仓库Hive答案 第9讲 ...
推荐文章
- 用好ASP.NET 2.0的URL映射-程序员宅基地
- C语言等级考试是把题目删了,历年全国计算机的等级考试二级C语言上机考试地训练题目库及答案详解(72页)-原创力文档...-程序员宅基地
- Microsoft Office显示正在更新无法打开的问题_正在更新microsoft 365和office-程序员宅基地
- 非常好的Ansible入门教程(超简单)-程序员宅基地
- 【Gradle-8】Gradle插件开发指南-程序员宅基地
- 使用PL/SQL Developer软件解锁_plsqldev表格锁怎么打开-程序员宅基地
- 【Windows Server 2019】Web服务 IIS 配置与管理——配置 IIS 进阶版 Ⅳ_iis默认路径-程序员宅基地
- 网络中的各层协议_发送消息时各层协议-程序员宅基地
- UCRT: VC 2015 Universal CRT, by Microsoft_vc15rt-程序员宅基地
- 关于EntityFramework 7 开发学习_entiry framework 7 书籍-程序员宅基地